
Penguin Solutions ($PENG): Solving the AI Inference Memory Wall
A deep dive into Penguin’s CXL memory infrastructure thesis, the real role of photonics, and why inference is becoming memory-bound.


1. Introduction
I am writing this piece because of recent tweets from Serenity about $PENG.
Before anything else, let me say it directly: Serenity is right about the photonics hype. There has been a wave of investors framing Penguin as a silicon photonics play, and that framing is wrong. Penguin does not fabricate optical chips, does not make lasers, does not produce transceivers. If you want a pure-play photonics exposure, the answer is Marvell (post-Celestial acquisition), Coherent, or Lumentum. Not Penguin.
But here is what I think Serenity missed, and what I want to address in this piece: 90% of the investors who are long Penguin (myself included) did not initiate the position because of photonics. We initiated because of CXL, KV cache, and the memory wall. The photonics piece is a side story for us. The main story is something else entirely.
So this article is a deep dive on what Penguin Solutions actually is, what it actually does, why I bought it last week, and where the photonics question fits inside the larger picture. I will be as objective as I can given that I hold a position.
Let’s go.
2. The macro context: why inference broke the GPU story
For two years, the AI infrastructure conversation was a GPU conversation. NVIDIA earnings, Blackwell ramps, hyperscaler capex.
To train an AI model (LLM), you need a lot of processing power. Training is compute-bound. The GPU is the binding constraint. That part of the story has not changed.
But to use a model day-to-day, you run inference. And inference is memory-bound, not compute-bound.
Every time an LLM generates a response, the system processes text token by token. To keep the thread of the conversation and avoid recalculating the entire sequence on every interaction, the AI architecture temporarily stores the historical context data in an intermediate memory tier called the KV cache (Key-Value cache).
The KV cache is the model’s working memory. It grows with context length and with the number of concurrent users. In a macro scenario of exponential AI adoption, where context windows are expanding (people are now asking models to process entire documents, full financial statements, complex regulatory analyses) and where thousands of users query simultaneously, the KV cache grows proportionally.
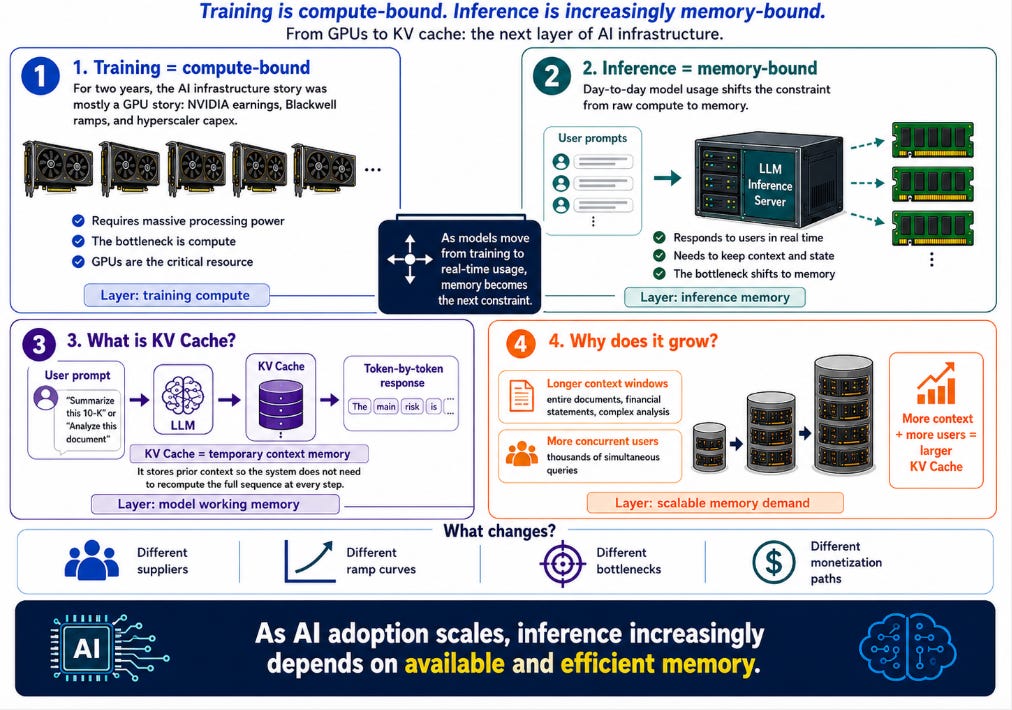
2.1 Where the “memory wall” begins
GPU memory (HBM) is extraordinarily fast but extraordinarily limited. It is also extraordinarily expensive to scale. When the KV cache grows beyond what HBM can hold, the system either has to recompute tokens redundantly (which destroys latency and Time-to-First-Token), or has to offload to slower storage like NVMe (which destroys latency even harder), or has to buy more GPUs (which destroys the unit economics of inference).
The third option, “buy more GPUs,” is the default answer the market has been pricing for two years. But here is what the data is saying right now:
A paper by Gholami and others (2024, arXiv) quantified the divergence. AI model compute requirements grew about 410x every two years. Memory bandwidth scaled only 1.6x per two years. Interconnect bandwidth grew 1.4x per two years.
GPUs became much faster than the memory systems feeding them.
That creates a structural problem in inference. In inference, especially when the model responds token by token, the situation changes.
To generate each new word, the model needs to constantly access memory: the model’s weights, the previous context, the KV cache, etc. The problem is no longer that the GPU cannot calculate, but that the GPU does not receive the data fast enough.
Analogy:
You have a Ferrari capable of going 300 km/h, but it is stuck on a single-lane road full of traffic. The engine is extremely powerful, but it cannot use all that power because the flow of cars ahead is too slow.
That is what happens to the GPU during inference.
This is the core problem of inference. Modern GPUs have enormous compute capacity, but during token-by-token generation they often spend a lot of time waiting for data to arrive from memory. The bottleneck is no longer the ability to calculate. The bottleneck is the ability to feed the GPU fast enough.
This is the memory wall.
And here is the independent confirmation from the IDM side. Jeremy Werner, Micron’s Senior Vice President and General Manager of the Data Center Business Unit, said the following in a May 2026 interview on The Circuit Podcast:
Memory has become a key strategic asset for breaking bottlenecks in data center inference and is also the core support for training the world’s most advanced models. I don’t think this trend will slow down.
When the memory IDM (Micron) and the system integrator (Penguin) describe the same constraint from opposite ends of the value chain, the framing is not marketing positioning.
In addition, there is a popular thesis going around that cheaper tokens will reduce total AI infrastructure spend. The argument is that as models get more efficient and compute gets cheaper, total spending compresses.
That thesis is wrong.
Cheaper tokens do not reduce total compute spend. They unlock products that consume more tokens, longer context windows, and larger KV caches. AI demand is no longer limited only by FLOPs. It is limited by memory architecture. Lower per-token cost expands the use case set, which expands aggregate token consumption. The math goes the other way.
So the new question becomes:
How do you keep those GPUs fed with memory, context, and data without breaking the economics of inference?
That is the question Penguin Solutions is answering.
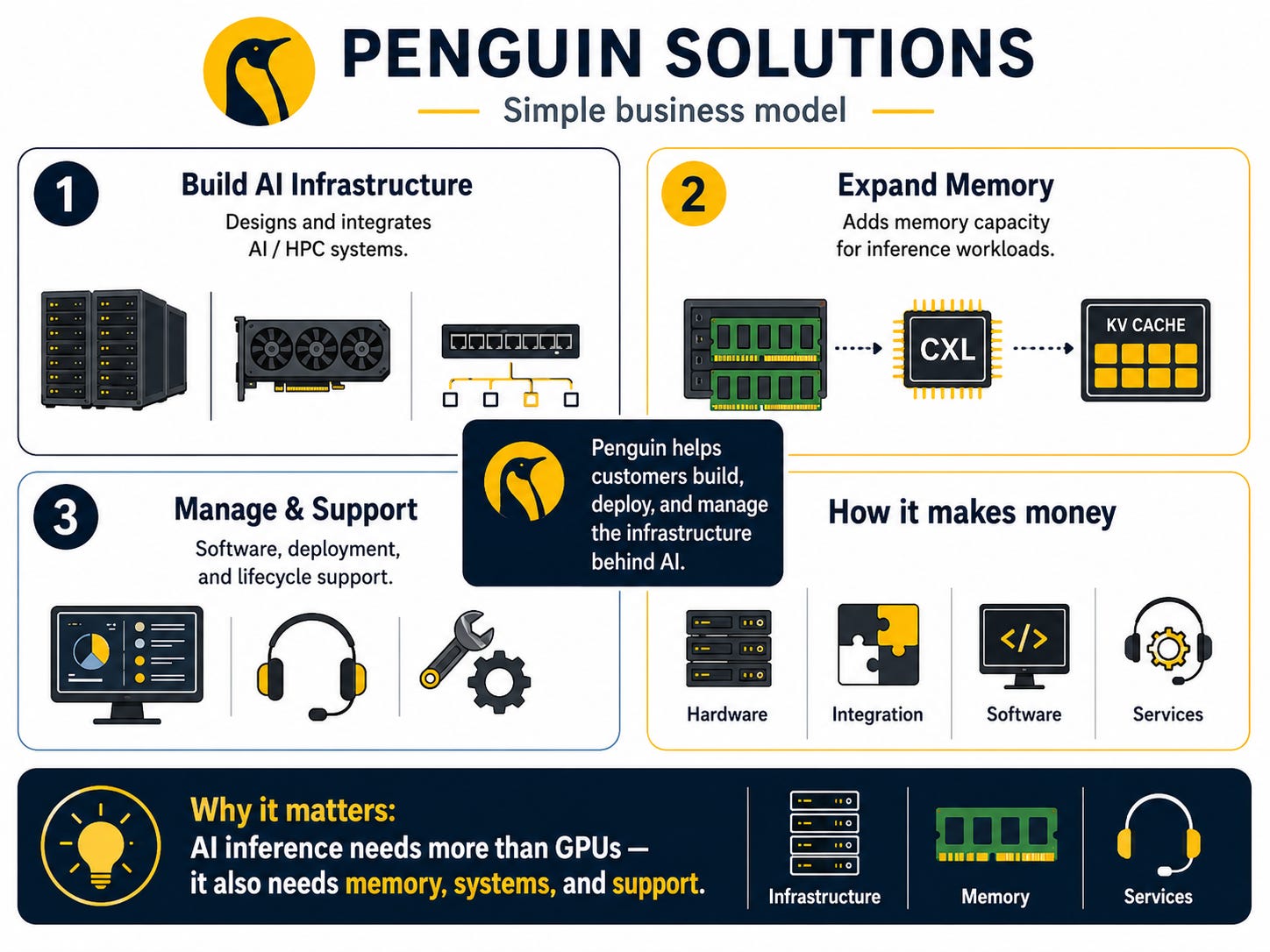
3. What is Penguin Solutions, actually
Penguin Solutions is not a new company. It is the combination of two heritage businesses that the market is just now starting to value correctly together:
1. SMART Modular Technologies is the memory engineering heritage. Nearly three decades of building precision memory modules for industrial, defense, networking, and now AI infrastructure customers. The DRAM module manufacturing know-how, the conformal coating IP for liquid immersion, the relationships with Samsung, Micron, SK Hynix as primary suppliers. This is the “memory engineering” half of the company.
2. Penguin Computing is the high-performance computing (HPC) heritage. Acquired in 2018. Penguin was one of the early commercializers of the Beowulf architecture (cluster-based HPC). They built supercomputers for governments and Tier 1 enterprises before “AI factory” was a marketing term. They have integrated more than 3.3 billion GPU runtime hours of operational data, which becomes important when we get to the software side.
In February 2025, the company rebranded the broader platform around what it now calls the AI factory architecture. New CEO Kash Shaikh (since early February 2026) reorganized the platform around six elements:
ICE ClusterWare: the cluster orchestration software (more on this later)
MemoryAI: the CXL KV cache server family (this is the new product line that drives the equity thesis)
Advanced Computing: the HPC and AI hardware systems (the heritage Penguin Computing business)
OriginAI: reference architectures and AI factory designs
End-to-end services: deployment, integration, ongoing operations
Partner ecosystem: NVIDIA Elite Partner, SK Telecom strategic anchor, Dell distribution, CDW channel


The SK Telecom anchor is critical context. On December 13, 2024, Penguin closed a $200 million strategic investment from SK Telecom via Astra AI Infra LLC. The investment took the form of 200,000 convertible preferred shares at $1,000 per share, with SKT receiving board representation rights, pro-rata rights, and registration rights. SK Telecom is a sister company to SK Hynix within the SK Group, which means Penguin has direct relationship depth into the most aggressive memory IDM in the world. At a moment when memory supply is the binding constraint on AI infrastructure, having that relationship matters more than the market has yet priced.
3.1 MemoryAI KV Cache Server: what Penguin actually launched at GTC
On March 16, 2026, at NVIDIA GTC in San Jose, Penguin announced the MemoryAI™ KV Cache Server. Per the company’s own press release:
The industry’s first production-ready KV cache server that utilizes CXL memory technology to address the critical ‘memory wall’ challenge in AI inferencing.

Let me explain what this actually means in plain terms.
Inside a modern AI server, you have a memory hierarchy:
HBM (High Bandwidth Memory, attached to the GPU): extremely fast, extremely limited (80-192 GB per GPU), extremely expensive
System DRAM (server motherboard memory): fast, more capacity (1-2 TB), more affordable
NVMe SSD (server storage): slow, very high capacity, very cheap
The problem with current AI inference deployments is that the KV cache mostly has to live in HBM because everything else is too slow. Once HBM fills up, the system has bad options.
MemoryAI introduces a new tier: CXL-attached memory.
CXL (Compute Express Link) is a high-speed interconnect that lets a server attach and share additional memory outside the GPU. The MemoryAI KV Cache Server is a 4U appliance with up to 11 terabytes of memory (3 TB of DDR5 main memory + up to 8x 1 TB CXL Add-in Cards).

The performance numbers from Penguin’s launch materials:
10x faster than NVMe-based caching for KV cache workloads
3.8x faster than RDMA approaches. The practical alternative to CXL local memory is pulling KV cache from another server via InfiniBand or similar, which adds network latency that CXL eliminates.
Native compatibility with NVIDIA Dynamo (NVIDIA’s software architecture for KV cache memory offloading, released alongside GTC)
The framing from Penguin’s own press release is the most important data point in the entire equity thesis:
Penguin Solutions itself is telling investors that inference workloads are 70% memory-driven and 30% compute-driven. The GPU is no longer the constraint. The memory architecture is.
CEO Kash Shaikh said it directly on the Q2 FY2026 earnings call:
Model training was largely compute bound. Inference, however, agentic AI is memory bound and latency sensitive. We believe this is driving a re-architecture of the data center across compute, memory, interconnect, and software.
CTO Phil Pokorny added on the launch:
CXL-enabled KV cache technology delivers faster time-to-first-token, reduced time per output token, and increased overall end-to-end token throughput. These critical performance improvements enable enterprise-scale inference across many users that expect low latency and timely access to AI-generated insights.
And here is what makes MemoryAI different from every other CXL play in the market:
It is the only production-ready CXL-based KV cache server actually shipping at scale:
XConn Technologies and MemVerge demonstrated a joint CXL pool at SC25 in November 2025, but as a demonstration, not a shipping product.
SK Hynix has showcased memory-centric AI architectures with CXL pooling but has not productized them into a turnkey server.
Astera Labs ships Leo CXL Smart Memory Controllers, but those are silicon components, not an integrated system appliance.
Marvell (post-Celestial acquisition) has photonic memory technology in development, but commercial product is 2027+.
Penguin shipped a 4U production server with 11 TB of CXL-attached memory, NVIDIA Dynamo compatibility, and customers already in deployment as of Q2 FY2026.
Two specific customer wins disclosed on the Q2 call:
A tier-one financial institution purchased CXL-powered KV cache servers for an on-premise AI factory deployment.

A generative AI company building inference workloads placed a “substantial order for CXL cards” for KV cache offload.

I know you read “photonic memory appliance”. We are going to talk about it later.


Dollar values were not disclosed, but the customer categories are exactly the buyer profiles that justify the product. Financial services has regulatory pressure for on-premise inference. Generative AI companies have the technical sophistication to identify the bottleneck and the budget to solve it.
This is the product. Now the financials.
4. Financials
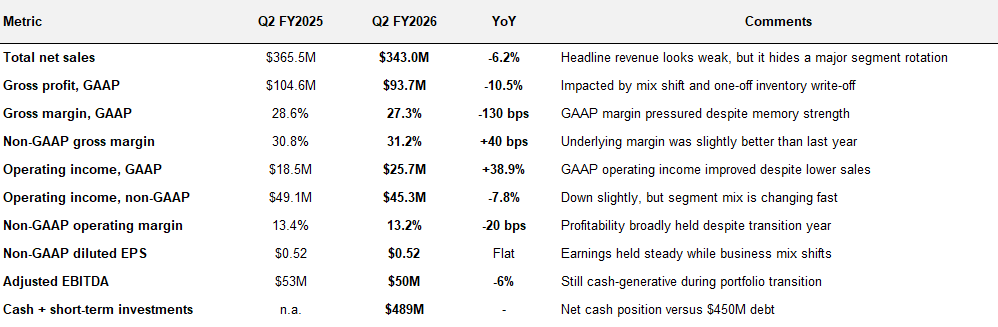
31.2% non-GAAP gross margin is structurally higher than any commodity AI hardware integrator. Supermicro, for comparison, reported gross margin of approximately 9.9% in its most recent results.
The gap is roughly 3x. That gap is what tells you Penguin is not a pure integrator. We will get to the moat that creates that gap in a moment.
One important one-time item in Q2: Penguin disclosed a $27.5 million GAAP gain (approximately $32 million cash) from the disposition of its equity stake in Celestial AI, the photonic memory company that was acquired by Marvell Technology in February 2026 for approximately $3.25 billion. Penguin was an early Series B and Series C investor in Celestial. The $27.5M gain is excluded from the non-GAAP numbers above, but the cash hit the balance sheet and contributed to the $489M cash position.
The headline -6% revenue decline obscures the segment-level story:

The Integrated Memory segment grew 63% YoY in a single quarter. That is the AI-driven memory demand thesis converting into actual revenue. CFO Nate Olmstead on the call:
On the memory outlook, we’re really pleased with the demand that we’re seeing as well as the favorability that we see in the pricing environment. For the increase that we’re seeing in the second half, that’s majority pricing, but demand is also very strong. AI-driven demand is just very strong. In fact, to get to the high end of that outlook really just refers to our ability to secure materials, which is really the only inhibitor.
That is the same allocation language Samsung, SK Hynix, and Micron used on their Q1 calendar 2026 earnings calls. The memory cycle is in allocation mode, not commodity mode.
The Advanced Computing decline of -42% YoY needs honest framing. It is driven by two specific items:
The ongoing Penguin Edge wind-down (legacy hardware business being deliberately exited)
The non-recurrence of a large hyperscale hardware sale from Q2 FY2025
Strip out those two effects and the underlying non-hyperscale AI/HPC business grew 50% YoY in the first half of FY2026. Seven new AI/HPC logos closed in H1 FY26 versus three in H1 FY25.
4.1 Guidance
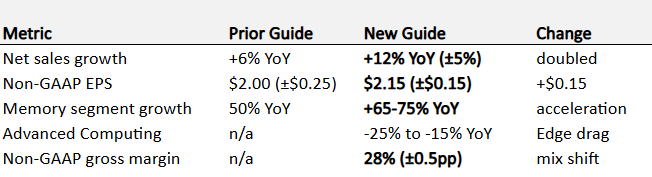
The doubling of the revenue growth guide in a single quarter is the data point that signals management has visibility on the underlying memory demand strength and the MemoryAI customer pipeline conversion. Companies do not double growth guidance on speculation.
5. The photonics question.
What Serenity got right, and what changed in Q2
This is the section that directly addresses what Serenity raised. Before I started this piece, I would have framed it as a clean binary: PENG is not a photonics company, the Celestial position was sold, that exposure is monetized and done. End of story.
BUT then I went back and read the Q2 FY2026 earnings call transcript again. And the framing changed.
Let me walk through what the call actually said, because this is the part where retail investors who only read headlines are getting the story wrong.
What Serenity got right
The photonics-hype framing is wrong. PENG does not fabricate optical chips, does not make lasers, does not produce transceivers. Marvell (post-Celestial), Coherent, and Lumentum are the photonics pure-plays. If your thesis on PENG was “this is a silicon photonics manufacturer,” your thesis was wrong, and Serenity was right to push back on it (again, this was 0.1% of investors).
What changed in the Q2 call
CEO Kash Shaikh disclosed on the April 1, 2026 earnings call something that the market has not yet priced. Direct quote from the prepared remarks:


And on the Q&A, when asked directly how CXL and photonics interact:

Translate that out of management-speak:
PENG has an active product in development called PMA (Photonic Memory Appliance, formerly OMA). This is a real product, not a marketing concept. The naming change from OMA to PMA happened between the Q1 and Q2 calls.
The Celestial AI partnership continues with Marvell. PENG sold its equity stake in Celestial when Marvell acquired it ($27.5M gain in Q2). But the co-development partnership did not end. Marvell inherited it. PENG is now working with Marvell on the PMA.
The PMA is the “next level” version of the MemoryAI KV Cache Server. Same architecture (external memory appliance for AI workloads), different physical layer (photonic interconnect instead of CXL electrical). The product roadmap is sequential: CXL MemoryAI shipping today, PMA in active development for the next architecture wave.
The exposure is product-level, not just equity-level. The equity stake was monetized and is gone. The product partnership is active and ongoing.
Why CXL and photonics are sequential, not competitive
The instinct is to read “photonics is the next level” as “photonics is faster than CXL” and assume PMA replaces MemoryAI when it ships. That framing misses what the two technologies actually do.
The difference between CXL and photonics is not speed. It is distance.
CXL electrical works within a server. Copper interconnects, maximum physical reach of approximately 1.5 meters. That is enough to connect additional DRAM memory inside the same server box as the GPU. The MemoryAI KV Cache Server with 11 TB of CXL-attached memory operates inside this constraint: it sits next to the GPU servers in the same rack.
That solves the first bottleneck: memory capacity per server. The GPU runs out of HBM, the CXL appliance gives it 11 more terabytes within reach.
But AI data centers are evolving toward a different architecture. Multiple GPUs across multiple servers across multiple racks all sharing a unified memory pool. At 10+ meters of physical distance between racks, copper interconnects degrade signal and inject latency that destroys the benefit. Electrical CXL cannot reach that far.
Photonics can. Fiber optic and silicon photonics transceivers move data over tens to hundreds of meters without signal degradation. That solves a different bottleneck: memory pooling across the entire data center.
So the two products serve sequential problems:
CXL MemoryAI today: solves “the GPU ran out of memory inside its own server”
PMA tomorrow: solves “the entire data center needs to share one gigantic memory pool”
When CEO Kash Shaikh says photonics provides “increased capacity to share the memory,” the keyword is share, across distances that electrical interconnects cannot cover. He is not saying photonics is faster. He is saying it scales to distances and pool sizes that CXL physically cannot.
Both bottlenecks exist. CXL is being deployed against the first one today. Photonics will be deployed against the second one when AI architectures need it (industry consensus: 2027-2028 for early deployments, 2029+ for at-scale adoption).
PENG is positioned across both. That is the actual roadmap.
How to think about it now
PENG is not a photonics pure-play. Marvell is. If you want a pure photonics investment, buy Marvell, Coherent, or Lumentum.
But PENG is also not a “photonics is irrelevant to this company” play, which is what most retail commentary has settled on after the Celestial sale was reported. The Q2 call disclosed that PMA is in active development in partnership with Marvell. That partnership is the operational continuation of the Celestial relationship, not its termination.
The honest frame:
Today’s revenue thesis is CXL. MemoryAI KV Cache Server, shipping to Tier 1 financial services and generative AI customers. This is what generates revenue in FY2026 and FY2027.
The next-architecture optionality is photonics. PMA in active development with Marvell. If CXL adoption scales as expected through 2026-2027 and the memory wall persists into 2028+, photonic interconnects become the obvious next step for AI memory architectures. PENG is positioned to ship the appliance layer when that transition happens.
If you are long PENG because of CXL and the memory wall today, you are in the right thesis. The PMA is upside optionality, not the primary reason to buy.
If you are long PENG because you think it is a photonics manufacturer today, your thesis is wrong, and you are eventually going to be disappointed.
Serenity was right to push back on the photonics-pure-play framing. The framing creates expectations that the business cannot deliver in the short term. But the underlying photonics roadmap exists, is disclosed primary, and is more advanced than most investors realize. The PMA disclosure on the Q2 call is the part that the market has not yet priced.
That is the photonics question, honestly answered.
6. The moat
Why PENG is not a commoditized integrator
Now we get to the question that determines whether the 31.2% gross margin is sustainable or whether it compresses to integrator-level margins (10-15%) over time.
This is the most important section of the piece.
For comparison, a pure server integrator like Supermicro reports gross margins of approximately 9.9% in its most recent results. That is what commodity AI hardware integration looks like. If Penguin’s gross margin compresses to that level, the equity is dramatically overvalued.
If Penguin’s gross margin holds in the 28-32% range (where it sits today), the equity is correctly priced or undervalued.
At $2.35B market cap and approximately $2.3B enterprise value, PENG trades at roughly 1.7x forward EV/Sales on the raised FY2026 guide. For context, Supermicro trades at approximately 1.5-1.8x forward EV/Sales.
The market is currently pricing PENG at integrator multiples despite a 31.2% non-GAAP gross margin (vs Supermicro’s 9.9%), 24% adjusted EBITDA margin, +63% Integrated Memory growth, and the only production-ready CXL KV cache server in the market.
The question is why the market is already pricing it as an integrator despite the margin profile. The answer depends on what justifies the gross margin structurally. If the margins are real and sustainable, the equity has room to re-rate. If they compress to integrator levels over time, the current valuation is approximately correct.
Five concrete moat elements determine which scenario plays out:
Moat 1: MemoryAI patent stack and the Conformal Coating IP
Penguin does not just integrate cooling. Through SMART Modular, they design and manufacture memory modules with a patented Conformal Coating that allows DDR5 RDIMMs to operate in dielectric fluid immersion without corrosion.
When AI rack density exceeds 45 kW per rack (which is what Blackwell and Vera Rubin require), passive air cooling stops working. The industry transitions to direct-to-chip liquid cooling and increasingly to single-phase and two-phase immersion systems.
The challenge: memory modules immersed in dielectric fluid degrade and corrode over time due to chemical interaction with the fluid.
SMART Modular solves this by applying a patented Conformal Coating: an ultra-thin polymer layer sprayed with precision over the memory modules. The layer hermetically seals the electrical contacts and silicon against corrosion and oxidation without insulating thermal transfer from the chips. The modules can sit in dielectric fluid tanks for years without degradation.
No integrator can replicate this. It is materials science IP backed by manufacturing infrastructure.
Moat 2: ICE ClusterWare and AIM software
A large AI cluster is not a collection of independent computers. It functions as one giant machine. Without extremely advanced orchestration software, the GPUs in a data center hit constant bottlenecks and operate at maybe 50% of their theoretical value.
Penguin provides its own proprietary software: ICE ClusterWare (formerly Scyld ClusterWare) and the AIM module (Autonomous Infrastructure Management).
ICE ClusterWare automates the configuration of bare-metal AI and HPC systems, allowing thousands of servers to be set up, updated, monitored, and managed as one coordinated cluster.
AIM is the differentiator. It leverages 3.3 billion GPU runtime hours of telemetry data accumulated by Penguin to apply predictive maintenance algorithms. The software monitors thermal, electrical, and performance signals on each GPU node in real time. Using the runtime hours dataset, it detects early signs of failure and automatically isolates or remediates problematic components before they cause an interruption to training or inference workloads.
In plain terms: Penguin doesn’t just help customers build AI supercomputers. It helps keep them online. That is recurring software revenue that has no analog in pure integrator businesses.
Moat 3: SMART Modular memory engineering heritage
Nearly three decades of precision memory packaging. Long-standing relationships with Samsung, Micron, SK Hynix as primary suppliers. The CXL NV-CMM E3.S 2T module passed CXL Consortium certification in January 2026 and was added to the official CXL Integrators List, making Penguin one of very few interoperable silicon providers ready for mass deployments of in-memory databases.
This is preferred allocation access during a memory shortage. The same dynamic that gives Apple priority allocation from TSMC during a foundry shortage applies here. When the memory IDMs are choosing who to allocate, they prioritize the customers with longest history and deepest engineering relationships. Penguin sits in that tier.
Moat 4: NVIDIA Elite Partner + DGX-Ready Managed Services
Penguin is recognized as an NVIDIA Elite Partner and a DGX-Ready Managed Services Provider. The company has direct hardware-level integration relationships with NVIDIA for next-generation architectures.
Reference deployment: Penguin worked with Meta’s operations team on hardware integration and infrastructure setup for accelerated H100/H200 GPU clusters, coordinating Pure Storage storage system connectivity over low-latency InfiniBand networks.
You don’t get that level of co-engineering access by being a generic integrator.
Moat 5: SK Telecom alliance and the Haein supercomputer
The most important strategic alliance Penguin has formed is with SK Telecom and SK Hynix.
In December 2024, SK Telecom completed the $200M strategic investment in Penguin. At CES 2025, the partnership expanded into a three-way agreement with SK Hynix for research, development, and commercialization of next-generation AI Data Center (AIDC) infrastructure.
The first major demonstration of this synergy is the Haein supercomputer, one of South Korea’s most advanced sovereign AI infrastructures. Put into production in August 2025 in a record installation time of just two months. Key specifications:
Over 1,000 NVIDIA Blackwell B200 GPUs integrated into the SK broadband Gasan data center
50+ miles of precision optical fiber cabling orchestrated
Combined software stack: Penguin’s ICE ClusterWare + SK Telecom’s Petasus AI Cloud Kubernetes virtualization platform, enabling GPU-as-a-Service (GPUaaS) at market scale
The strategic cooperation with SK Hynix guarantees SMART Modular (Penguin) joint development and preferred allocation of advanced CXL memory and HBM silicon wafers, mitigating supply chain bottleneck risks at a moment when memory supply is the binding constraint on the entire AI infrastructure industry.
That is the moat. Five concrete elements, each defensible. The market is starting to price this. Penguin still has room to re-rate.
One more proof point: the strategic divestment
In March 2026, Penguin completed the sale of Zilia Technologies (its Brazilian commodity memory module subsidiary) to Lexar for $46.08 million.
This matters editorially. The new CEO Kash Shaikh’s leadership team is explicitly exiting the commodity hardware manufacturing business and concentrating capital into high-margin, high-value-added AI infrastructure solutions. The Zilia sale is the operational proof that the strategic repositioning is real, not just messaging.
A company that is becoming a pure integrator does not divest its commodity manufacturing arms. A company that is becoming a value-added platform does.
7. Management
This part is genuinely insane
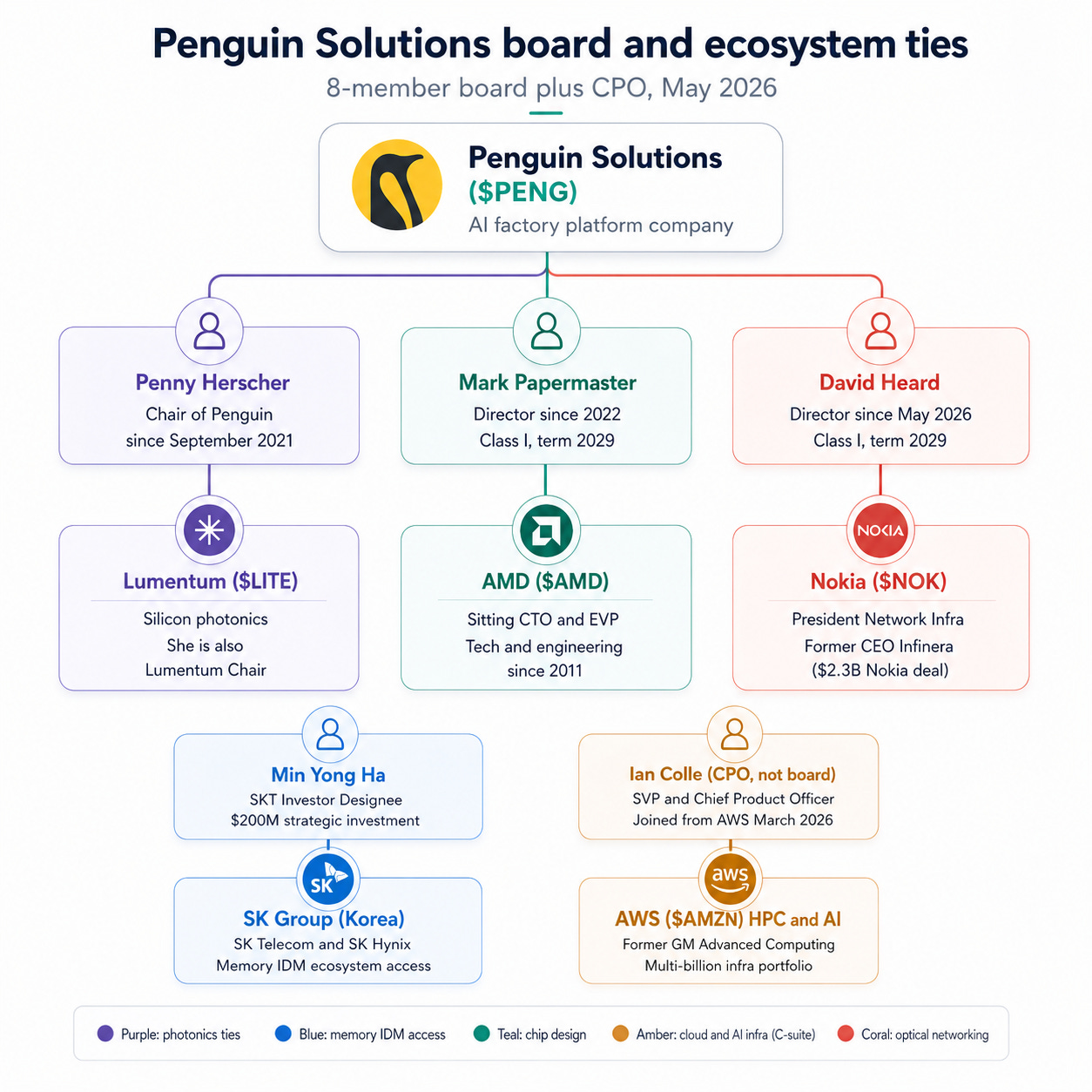
I have to stop here for a moment because the board composition at Penguin Solutions is the part that almost made me triple my position size after I dug into it.
Most retail investors do not look at boards. They should, especially for AI infrastructure plays where the technical signal is buried inside who is willing to associate their reputation with the company.
On May 18, 2026, Penguin Solutions filed an 8-K announcing it had expanded its board to eight members and appointed:
1. David Heard, President of Network Infrastructure at Nokia ($NOK), as a Class I director and member of the Compensation Committee, with a term running to the 2029 annual meeting.
2. Penny Herscher - Chair of the Board (since 2022). Penny is concurrently Chair of the Board at Lumentum Holdings ($LITE), one of the largest silicon photonics and optical component manufacturers in the world. She has been a director at Penguin since September 2021. Prior board service includes Rambus (2006-2018), Cadence Design Systems (EVP and CMO), and CEO roles at FirstRain and Simplex Solutions. Cambridge mathematics. Two decades at the intersection of EDA, semiconductors, and photonics governance.
3. Mark Papermaster - Class I director (since August 2022). Concurrently the sitting Chief Technology Officer and EVP of Technology and Engineering at AMD ($AMD) since 2011. Before AMD: Silicon Engineering Group at Cisco, SVP of Devices Hardware Engineering for iPod and iPhone at Apple, and multiple roles in technology and server development at IBM. He is responsible at AMD for technical direction and product development including microprocessor design, I/O and memory, system-on-chip methodology, and advanced research. Member of the Global Semiconductor Alliance Board. Engineering background in microprocessor and memory design at the highest tier of the industry.
4. David Heard - Class I director (just appointed, May 18, 2026). Concurrently President of Network Infrastructure at Nokia ($NOK) since July 2025, where he sits on Nokia’s Group Leadership Team and reports directly to CEO Justin Hotard. He joined Nokia in February 2025 via Nokia’s $2.3 billion acquisition of Infinera, where he had served as CEO since June 2017. Before Infinera: JDS Uniphase, BigBand Networks, Somera Communications, Lucent Technologies, and AT&T. Four decades of senior leadership inside optical networking and photonics.
That Infinera deal is the part most retail investors miss. Infinera was the photonic chip company that vertically integrated Nokia from a reseller of someone else’s photonics into a company with its own optical chips. Nokia Optical Networks grew 20% year-over-year in Q1 2026 and management raised Network Infrastructure full-year guidance from 6-8% to 12-14% on the back of that integration. The man who built that integrated optical business at Nokia just joined the Penguin Solutions board.
5. Min Yong Ha - Class III director (since December 2024). SK Telecom’s Investor Designee on the board, appointed under the terms of the $200M SKT strategic investment. SK Telecom is the sister company of SK Hynix within the SK Group, direct relationship pipeline into the most aggressive memory IDM in the world.
6. Mary G. Puma - Class II director (since July 2023). Former President and CEO of Axcelis Technologies (semiconductor capital equipment, ion implant systems for chip manufacturing) from 2002 to 2023. 25+ years inside the semiconductor industry.
7. Sandeep Nayyar . Class II director (since 2014), Audit Committee Chair. Long-tenured finance leadership at the board level.
8. Bryan Ingram and Maximiliane Straub round out the eight independent directors with deep technology operating and finance backgrounds.
And on the operating side, Ian Colle (Senior Vice President and Chief Product Officer since March 2026, not a board member) came over from Amazon Web Services, where he was General Manager of Advanced Computing and Simulation, the team that built and scaled AWS’s HPC and AI infrastructure portfolio into a multi-billion-dollar business from the ground up. Before AWS: Red Hat and Intel.
Now look at the network this composition creates.
Penguin Solutions has on its board the sitting Chair of one of the largest public photonics companies (Lumentum), the sitting CTO of one of the two largest public chip designers (AMD), the President of Nokia’s optical networking division (just joined), and a direct SK Telecom representative (which means SK Hynix ecosystem access). On the operating side, the Chief Product Officer came from AWS’s HPC and AI infrastructure team.
This is not the board composition of a commoditized integrator. This is the board composition of a company that the technical leadership of the AI infrastructure industry believes will become structurally important to where the industry is going.
What board composition tells you is who is willing to put their reputation behind the company. When the people who run AMD’s silicon engineering, Nokia’s optical networking, and Lumentum’s governance are all willing to associate themselves with Penguin, that is a signal that the technical thesis is real to the people who know the industry best.
8. Risks
1. Penguin Edge wind-down headwind. Roughly 14 percentage points of FY2026 net sales growth is being absorbed by deliberate Edge business exit. The optics of declining Advanced Computing revenue can obscure the underlying AI/HPC business inflection through FY2026. There is a real risk that the market views Penguin as a slowing-growth company through the back half of FY2026 even as the underlying business is accelerating.
2. Bookings-to-revenue lag. Penguin’s AI/HPC project deployments run 12-18 months from prospecting to revenue recognition. Shaikh acknowledged on the Q2 call:
Most of the bookings that we are expecting may not materialize into revenue for the second half of this fiscal, but we believe that it will have a positive impact obviously going into the first half of the next fiscal.
That means FY2026 numbers reflect prior-period bookings, not the current inflection. The reward comes in FY2027 if execution holds.
3. Gross margin pressure. Memory is a lower-margin segment than Advanced Computing services. The mix shift toward memory and higher memory input costs both compress consolidated gross margin. The full-year FY2026 28% non-GAAP GM outlook is below prior-year trajectory. Whether MemoryAI margins are accretive over time depends on attach rates of higher-margin services and ClusterWare software.
4. Customer concentration. Top ten end customers accounted for 66% of net sales in 2025 (vs 58% in 2024 and 60% in 2023). Two individual customers exceeded 10% of net sales individually in 2025. The concentration is increasing, which is consistent with the AI infrastructure thesis but adds single-customer dependency risk.
5. Photonics adoption ahead of CXL. If silicon photonics commercializes faster than expected (Marvell ships Celestial-based photonic memory products in 2026 rather than 2027+), CXL-based memory tiering could be displaced before Penguin’s MemoryAI line achieves full revenue ramp. I assign low probability to this, but it is real and asymmetric.
9. What you are actually buying with PENG 0.00%↑
Let me close with the framework that I am operating from, since you have come this far.
You are not buying a photonics company. You are buying a CXL memory wall play with a strategic partnership anchor (SK Telecom + SK Hynix) and the only production-ready KV cache appliance shipping at scale in the market.
You are buying a company with:
31.2% non-GAAP gross margin (vs 9.9% commodity integrator average) sustained by five concrete moat elements
+63% YoY memory segment growth with FY2026 guidance raised to +65-75%
Net cash position ($489M cash vs $443M debt, no maturities until 2029)
NVIDIA Elite Partner status and DGX-Ready Managed Services Provider designation
SK Telecom $200M strategic investment with board representation, anchored into the most aggressive memory IDM ecosystem globally
The Celestial AI $27.5M one-time windfall that strengthened the balance sheet
A production-ready CXL KV Cache Server (MemoryAI) compatible with NVIDIA Dynamo, shipping to tier-1 financial services and generative AI customers
An active Photonic Memory Appliance (PMA) in development with Marvell, as the next-architecture extension of MemoryAI when photonics matures
Six core platform elements (ClusterWare, MemoryAI, Advanced Computing, OriginAI, services, partner ecosystem) under a focused new CEO
A board composition that includes the Chair of Lumentum, the sitting CTO of AMD, the President of Nokia Network Infrastructure (former CEO of Infinera), and a direct SK Telecom representative — the technical leadership of the AI infrastructure industry has put its reputation behind this company
You are absorbing:
A FY2026 headline growth optics drag from Penguin Edge wind-down (14pp)
A bookings-to-revenue lag that pushes the visible inflection into FY2027
Customer concentration (66% in top ten)
Mix-shift gross margin pressure through FY2026
Memory cycle correlation
An asymmetric but low-probability risk that photonics scales faster than CXL
The framing question is whether you can hold a position through 6-12 months of headline optics that do not reflect the underlying business trajectory, in exchange for a position in the AI factory platform that I think wins the CXL memory tiering category for the next 3-5 years.
I made that bet last week.
That is what I am long $PENG.
If you want a photonics pure-play, Marvell or Coherent are the answer, not this. If you want the CXL memory wall infrastructure play with the only production-ready KV cache appliance in the market, a tier-1 strategic anchor with SK Hynix access, and a Photonic Memory Appliance in active co-development with Marvell as the next-architecture optionality, $PENG is the position.
Serenity was right that the photonics-pure-play framing is hype. PENG does not make optical chips, and pretending otherwise sets up the thesis to fail. But the underlying CXL memory wall thesis remains, the PMA roadmap is real and disclosed primary in the Q2 call, and that is the combined thesis I am invested in.
If you want the full 4-player Memory Wall map, I covered it in depth in Part 4 of The Bottleneck Map series:
Not investment advice. Disclosure: I own shares in $PENG, opened the position last week.
All claims trace to primary sources: Penguin Solutions 10-K, 10-Q, Q2 FY2026 earnings call transcript (April 1, 2026), Q2 FY2026 earnings release, NVIDIA GTC 2026 MemoryAI product launch announcement (March 16, 2026), Celestial AI / Marvell acquisition disclosure (February 2026), SK Telecom strategic investment disclosure (December 2024), Penguin Solutions 8-K filing for David Heard board appointment (May 18, 2026), Penguin Solutions DEF 14A Proxy Statement (FY2026 board composition), Nokia Group Leadership Team announcement (David Heard promotion July 1, 2025), and SEC filings from Vanguard, Invesco, FMR LLC, and William Blair.
Would SK Telecom partnership also imply connection with Anthropic?
That’s a very good question! SK hynix already has a relationship with Penguin, so an acquisition could make sense